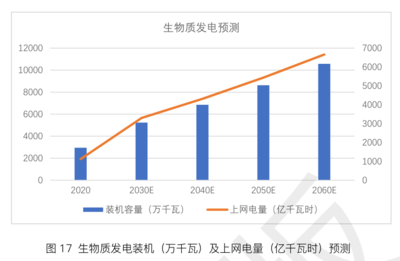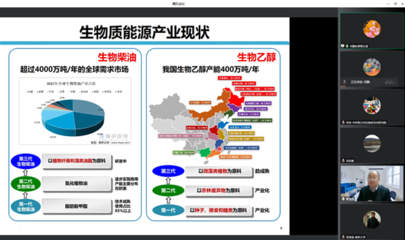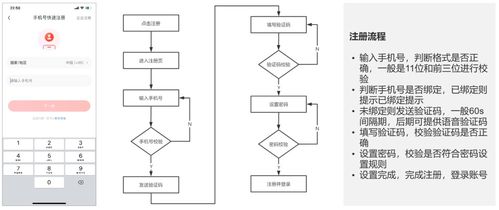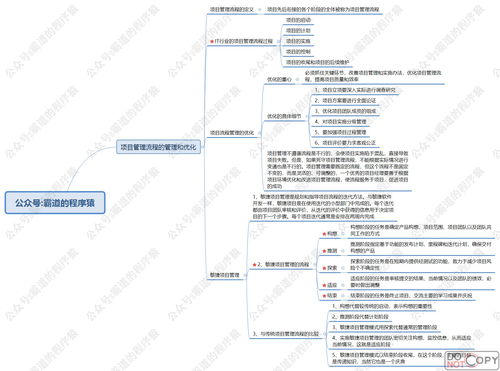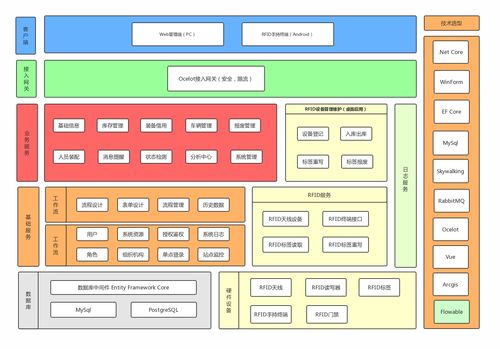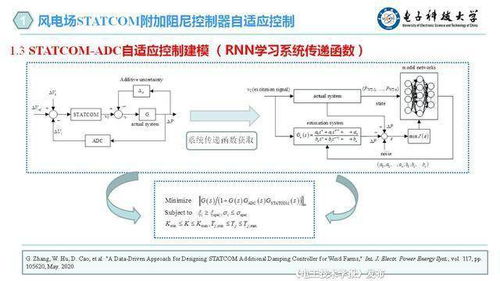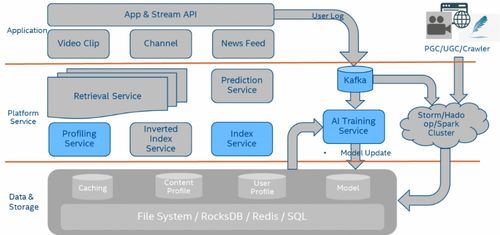
引言:信息過載的困境與存儲革命的曙光
在生物質能資源數據庫信息系統中,信息過載已成為制約其高效利用的關鍵瓶頸。隨著遙感監測、物聯網傳感器、科研文獻及產業數據的海量涌入,數據庫不僅容量劇增,數據形態也日趨復雜(如多光譜影像、時序監測數據、非結構化報告等)。傳統的關系型數據庫或簡單存儲方案,在應對這種高維度、多模態數據的實時查詢、分析與精準推薦時,往往力不從心,導致用戶難以從信息汪洋中快速鎖定高價值資源,決策效率低下。
與此以持久內存(PMem)、分布式對象存儲、智能分級存儲、非易失性內存(NVM)及新型索引技術為代表的“存儲黑科技”正蓬勃興起。這些技術不僅關注容量與速度,更強調數據存儲與智能處理的深度融合。本文將深入探討如何系統性地運用這些前沿存儲技術,構建一個能“理解”數據、主動服務的下一代生物質能資源信息平臺,從而從根本上解決推薦系統的信息過載問題。
一、存儲黑科技的核心武器庫
- 持久內存(PMem)與SCM(存儲級內存):打破內存與存儲的界限,提供接近DRAM的速度,同時具備數據持久化特性。這能將生物質能資源的熱點數據(如常用作物熱值模型、高頻查詢的地區資源圖譜)常駐于快速訪問層,使推薦引擎的實時特征計算和模型推理延遲降低數個量級。
- 分布式對象存儲與元數據智能管理:針對海量的非結構化數據(如衛星圖片、實驗視頻、PDF報告),分布式對象存儲提供近乎無限的橫向擴展能力。結合智能元數據標簽系統(如通過AI自動提取圖像中的作物類型、生長狀態),可以為每一份數據資產打上豐富的語義標簽,為后續的精準內容關聯與推薦奠定基石。
- 智能分層存儲與數據生命周期管理:基于訪問頻率、數據價值與計算需求,自動將數據在高速存儲(如全閃存陣列)、容量型存儲(如高密度HDD)及歸檔存儲(如藍光、磁帶庫)間動態遷移。例如,實時的秸稈供應動態數據存放在高性能層,而五年前的區域性氣候歷史數據可自動歸檔,確保存儲成本最優的不影響熱門數據的推薦響應速度。
- 新型索引與向量數據庫:傳統數據庫索引難以高效處理高維向量數據(如由文本、圖像特征嵌入生成的向量)。專用的向量數據庫或支持向量索引的新型存儲引擎,能夠對生物質能文獻內容、資源屬性進行深度語義編碼,并實現毫秒級的相似性檢索,這是實現“語義級”智能推薦(如“查找與某類厭氧發酵工藝最相關的案例研究”)的核心支撐。
二、構建“存儲-推薦”一體化智能系統架構
解決信息過載,并非簡單堆砌存儲技術,而是需要一套以智能推薦為牽引、以先進存儲為基石的協同架構:
- 數據湖倉一體化的存儲底座:構建融合數據湖(存儲原始多源數據)與數據倉庫(存儲清洗、治理后結構化數據)優勢的基座。利用對象存儲容納海量原始數據,同時通過高性能緩存和PMem加速層,支撐實時數倉對關鍵維度表的快速查詢,為推薦模型提供即時、一致的數據視圖。
- 近計算存儲與推薦模型協同:將推薦模型的部分預處理邏輯(如特征工程)下沉到存儲側。例如,在存儲節點內利用FPGA或智能網卡(SmartNIC)直接對流入的傳感器數據進行實時特征提取(如計算某一區域生物質資源的日均增長量),再將提煉后的特征向量高速推送至推薦引擎,大幅減少數據搬移開銷,提升從數據到推薦的端到端效率。
- 基于元數據與向量化的智能索引層:在存儲層之上,構建統一的、跨模態的智能索引層。所有生物質能資源數據,無論是文本報告、數值表格還是地理空間圖像,都通過AI模型轉化為富含語義的向量和結構化元數據,并存入向量數據庫和關系型索引中。當用戶發起查詢或瀏覽時,系統能同時進行關鍵詞匹配和深度語義相似性搜索,實現“既準又全”的混合推薦。
- 動態數據管道與反饋閉環:存儲系統需支持靈活、可伸縮的數據管道,實時吸納用戶與推薦結果的交互反饋(點擊、收藏、停留時長等)。這些反饋數據作為新的訓練樣本,與歷史數據一同被高效存儲和管理,并持續回流至推薦模型進行在線學習與更新,使推薦系統越用越智能,個性化程度不斷提升。
三、應用場景:信息過載如何被精準化解
- 場景一:科研人員尋找特定工藝的適配原料
- 過載表現:面對數百萬條原料特性數據,難以手工關聯工藝參數。
- 存儲黑科技方案:原料的全維度物化特性數據(如纖維素含量、含水率、灰分等)被預處理為特征向量,存儲于向量數據庫。當科研人員輸入目標工藝條件時,系統毫秒級檢索出物化特性最匹配的原料列表及相關研究文獻,并按關聯度排序推薦。
- 場景二:產業投資者評估區域資源潛力
- 過載表現:需要綜合氣候、土地、作物產量、政策、基礎設施等數十個來源的異構數據,整合分析困難。
- 存儲黑科技方案:分布式對象存儲統一管理所有源數據,智能元數據系統標記其時空屬性。智能分層策略將當前重點區域的多源數據保持在高速存儲層。推薦系統基于投資者關注的投資規模、技術路線等畫像,動態組合相關數據層,生成定制化的區域資源潛力分析報告與可比案例推薦。
- 場景三:技術人員追蹤技術前沿動態
- 過載表現:每日新增的專利、論文數量龐大,無法有效篩選。
- 存儲黑科技方案:所有新文獻的摘要和關鍵圖表被AI自動向量化并存入向量數據庫,與技術人員的歷史閱讀興趣向量進行實時相似度計算。基于持久內存的緩存層,使得這種大規模的向量比對能夠實時完成,在信息流中優先推薦最相關、最前沿的技術動態。
結論:邁向自適應的智能資源知識中樞
信息過載的本質是數據價值密度低與用戶認知帶寬有限的矛盾。通過將持久內存、智能分層、向量化索引等存儲黑科技與推薦算法深度集成,我們能夠構建一個不僅能“存得住”海量生物質能數據,更能“懂得”數據內涵、并主動“遞送”價值的智能系統。這樣的系統超越了傳統的信息查詢工具,演進為一個持續學習、動態優化的生物質能資源知識中樞。它不僅解決了當下的信息過載難題,更通過數據與知識的高效流轉,為生物質能領域的科研創新、產業規劃與商業決策提供了前所未有的敏捷性和洞察力,最終推動整個行業向數據驅動、智能決策的新范式加速邁進。